作业调度系统¶
主要作者
本文已完成
在中到大型的高性能计算集群上,为了高效地分配计算资源、管理用户作业、实施权限控制和计费等,通常会部署作业调度系统(Job Scheduler)。用户只能登录到少数(甚至一台)登录节点(login node),向调度系统提交作业请求;调度系统会根据资源使用情况和调度策略,将用户的作业分配到计算节点(compute node)上运行,并记录作业的状态和资源使用情况。
常见的开源作业调度系统包括 Slurm、OpenPBS、HTCondor 等。其中由 SchedMD 开发的 Slurm(Simple Linux Utility for Resource Management)是目前最流行的作业调度系统之一,广泛应用于各大超算计算中心和超级计算机。
本文不是用户指南
本文主要基于系统管理员的视角,重点介绍 Slurm 在 Debian 集群上的部署、管理。关于集群用户对 Slurm 客户端的使用(如 srun, sbatch, sinfo, squeue 等命令),请参考或者向用户提供如下资料:
Slurm 部署¶
前提要求
我们假设读者已经具备一定的基本概念,了解常见的名词(如 node、partition、job 等)。如果不熟悉这些概念,建议先阅读 Slurm 官方文档的概述,以及上面的用户文档。
此部分的撰写参考了 Slurm 资源管理与作业调度系统安装配置 的内容,并修改为使用 Debian 原生软件包,而非使用官方打包版本,或者从源码编译安装。
组件构成¶
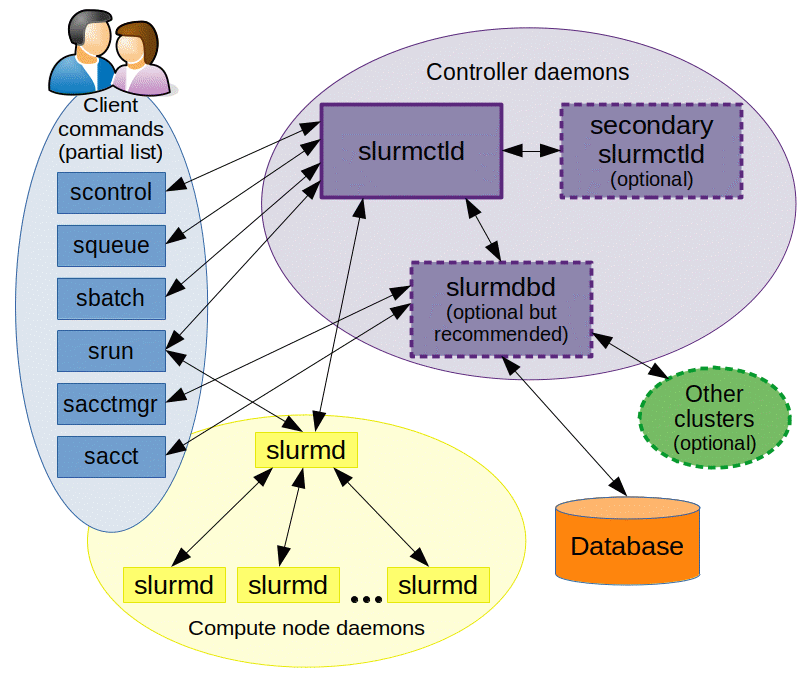
根据上图所示,Slurm 的控制守护进程(或称为服务端)主要由以下几个核心组件组成:
slurmctld:Slurm 控制守护进程,运行在管理节点上,负责资源管理和作业调度。slurmd:Slurm 计算守护进程,运行在每个计算节点上,负责执行分配给该节点的作业。slurmdbd(可选):Slurm 数据库守护进程,与其他进程通信,作为它们访问数据库的代理。
上述组件可以任意组合,管理员应当通过根据集群的功能、规模和冗余需求来决定具体的部署方案。例如,一个常见的中小型计算集群上的部署方案是:
- 登录/控制/数据库复合节点
foo00:部署slurmctld和slurmdbd,同时也安装 Slurm 客户端工具,供用户登录和提交作业。 - 计算节点
foo[01-15]:部署slurmd,不允许用户登录,作为计算节点执行用户作业。
前置要求¶
需要保证集群上的所有节点,可以通过主机名(hostname)解析所有节点的 IP 地址。建议使用静态 IP 或 DHCP 绑定,并配置好 DNS 服务,或者同步 /etc/hosts 文件。
运行控制守护进程的节点使用 munge 进行身份验证和通信,需要提前使用 apt 安装,并同步 /etc/munge/munge.key。munge 的正常工作还依赖于集群内时间的同步,请参阅 网络时间同步 进行配置。
munge 测试
可通过以下命令测试 munge 是否配置正确:
harry@foo:~$ echo 'Hello World' | munge | ssh bar unmunge
STATUS: Success (0)
ENCODE_HOST: foo (172.23.15.1)
ENCODE_TIME: 2025-11-23 23:03:26 +0800 (1763910206)
DECODE_TIME: 2025-11-23 23:03:26 +0800 (1763910206)
TTL: 300
CIPHER: aes128 (4)
MAC: sha256 (5)
ZIP: none (0)
UID: harry (1000)
GID: harry (1000)
LENGTH: 12
Hello World
统一的文件系统(如 NFS 或分布式文件系统)、网络配置和用户管理(如 LDAP)并非部署任何作业调度系统的强制要求,但通常是高性能计算集群的基础设施。请参阅本项目中的其他文档对此部分进行配置。
Slurm 配置文件¶
Slurm 需要的所有配置文件均存储在 /etc/slurm 下,管理员务必时刻保证集群中所有节点上文件内容一致(Slurm 会检查 hash),否则可能导致不可预期的错误。目前推荐的方式是使用 Configless Slurm(见后文),仅在管理节点上维护配置文件,其他节点实时进行拉取,以减少管理负担。
Debian 打包的 Slurm 没有提供默认配置文件,可通过官方的 Configuration Tool 生成 slurm.conf,并根据实际情况进行修改。一些关键的配置项包括:
ClusterName,SlurmctldHost,NodeName:顾名思义,按实际情况填写即可。SelectType:推荐使用select/cons_res,以支持对不同类型资源(如 GPU)的管理。SelectTypeParameters:根据实际情况填写,如CR_Core_Memory。ProctrackType,JobAcctGatherType: 均推荐使用cgroups类型的插件。AccountingStorageType: 如果安装 slurmdbd 则设置为accounting_storage/slurmdbd,并对应修改连接信息相关的配置。
对于配置文件的详尽解释,请参考官方文档的slurm.conf 章节,亦可参阅Slurm 资源管理与作业调度系统安装配置中的示例配置文件。
slurm.conf 的底部是对所有节点(node)和分区(partition)的定义,根据实际情况修改即可。如果需要配置 GRES 资源(如 GPU),则还需要额外提供 gres.conf 文件描述每个节点上的设备情况,或者使用 NVML 等插件进行自动检测。
如果需要 Slurm 对资源分配施加控制,尤其是限制用户对 GRES 的使用,则还需要提供 cgroup.conf 文件,并打开(默认不启用的)相关选项:
如此配置下,slurmd 会在计算节点启动作业时自动创建和管理相应的 cgroups,从而实现对资源的限制和隔离,避免用户占据未申请的资源,影响其他用户的作业运行。需要注意:目前 cgroups v1 已被绝大部分用户(如 Slurm、容器运行时、systemd 等)标记为过时,因此使用的是 cgroups v2。
如果修改了任何 slurm 配置文件,通常需要执行 scontrol reconfigure 使得修改生效;在部分情况下,可能还需要重启 slurmctld。在一般情况下,重启 slurmctld 不会影响正在运行的作业,也不会导致作业丢失,但依旧需要谨慎操作。
数据管理:slurmdbd¶
slurmdbd 是其他守护进程访问数据库的代理,可以避免在配置文件中直接暴露数据库连接信息。目前 slurmdbd 只支持 MySQL/MariaDB 作为后端,并只支持通过网络连接(而非 UNIX Domain Socket)。
注意备份数据库
Slurm 数据库中存储了用户组织关系、作业历史记录、资源使用情况等重要信息,务必定期备份数据库,以防止数据丢失。
slurmdbd 需要单独安装,并提供 /etc/slurm/slurmdbd.conf 配置文件,指定数据库的连接信息和认证方式。此文件只需要保留在运行 slurmdbd 的节点上,不需要复制到其他节点,并且文件权限必须为 600。
多个不同的 slurm 集群在技术上可以共享同一个 slurmdbd,但作者不推荐这样做,除非有明确的需要(如同样的用户群体需要访问多个集群的资源,又确实无法实现统一管理)。
管理节点:slurmctld¶
在管理节点上安装并启用 Slurm 控制守护进程:
touch /etc/slurm/slurm.conf # 填入相关配置
apt-get install -y slurmctld slurm-client
systemctl enable --now slurmctld
此时运行 sinfo,应当能看到集群的分区和节点信息。由于没有 slurmd 在计算节点上运行,所有节点都应该均显示为 UNK 状态。
计算节点:slurmd¶
此时在装有客户端的节点上运行 sinfo,应当能看到启动了 slurmd 的节点的状态转变为 idle。执行 srun hostname,可以看到作业确实被分配到了计算节点上运行。再运行 sacct -a,可以看到作业的记录已经被写入数据库。这样,一个基本的 Slurm 集群就搭建完成了。
如果需要使用 Slurm 管理硬件,则需要保证 gres.conf 中提及的设备文件在 slurmd 启动前已经存在,否则 slurmd 会因为找不到设备而无法启动,或者将自己标记为 DOWN 的不可用状态(具体行为根据版本不同而有变化)。一个缓解办法是,让 slurmd.service 依赖 systemd-modules-load.service,即执行 systemctl edit slurmd,增加:
并在 /etc/modules-load.d/ 下创建配置文件,保证相应的内核模块在系统启动时被加载(如 nvidia)。或者,仅针对于 NVIDIA 设备,也可以直接依赖于 nvidia-persistenced 服务,或者 nvidia-modprobe 工具。
权限管理与 QoS¶
Slurm 的权限管理依赖于其账户数据库,因此需要 slurmdbd 的支持。管理员可以通过 sacctmgr 命令行工具对账户数据库进行管理,包括创建和删除用户、组、账户和 QoS 等。Slurm 的权限实体是一个四元组:(user, account, cluster, partition),其中:
- user 是提交任务的 Linux 登录用户名;
- account 是用户可所属的账户,这是一个多对多的关系(如
srun -A foo可指定不同的用户),但每个用户只能有一个DefAccount,即默认账户;账户通常用于组织用户和计费; - cluster 是集群名称,对应
slurm.conf中的ClusterName,一般不需要修改; - partition 是可选的,不提供则表示对所有分区生效。
在此模型下,Slurm 提供了非常丰富的权限、资源控制手段,包括硬限制、配额、QoS 等,管理员可以根据实际需求进行配置和管理。由于内容较为繁杂,且与具体的集群使用场景密切相关,本文不再赘述,用户可以参考 Accounting and Resource Limits 和 Resource Limits 等文档。
需要特别注意的是,为了正确应用任务优先级,需要显式在配置中启用 Multifactor Priority Plugin,并恰当地配置优先级的计算公式中各项系数;否则,QoS 中的优先级效果可能无法体现。
注意打开配置
为了使得设置生效,需要正确配置 slurm.conf 中的 AccountingStorageEnforce 选项,常见的值是 associations,limits,qos,safe。
示例配置
下面是作者在管理的某个 Slurm 课程集群上运行 sacctmgr show qos 的输出,展示了三个 QoS 分组的配置情况:
Name Priority GraceTime Preempt PreemptExemptTime PreemptMode Flags UsageThres UsageFactor GrpTRES GrpTRESMins GrpTRESRunMin GrpJobs GrpSubmit GrpWall MaxTRES MaxTRESPerNode MaxTRESMins MaxWall MaxTRESPU MaxJobsPU MaxSubmitPU MaxTRESPA MaxJobsPA MaxSubmitPA MinTRES
---------- ---------- ---------- ---------- ------------------- ----------- ---------------------------------------- ---------- ----------- ------------- ------------- ------------- ------- --------- ----------- ------------- -------------- ------------- ----------- ------------- --------- ----------- ------------- --------- ----------- -------------
normal 5 00:00:00 cluster DenyOnLimit 1.000000 cpu=112 00:02:00 5
lab-ta 10 00:00:00 cluster 1.000000
lab-out 0 00:00:00 cluster DenyOnLimit 1.000000 00:05:00 3
normal是所有选课学生,优先级系数为 5,每个任务最多使用 112 个 CPU 核心,最长运行时间为 2 分钟,每个用户最多同时提交 5 个任务,超过限制的任务会被拒绝。lab-ta是课程助教,优先级系数为 10,没有其他限制。lab-out为其他用户,优先级系数为 0,每个任务最长运行时间为 5 分钟,每个用户最多同时提交 3 个任务,超过限制的任务会被拒绝。
此集群 slurm.conf 中的优先级相关配置是:
PriorityType=priority/multifactor
#PriorityDecayHalfLife=14-0
#PriorityUsageResetPeriod=14-0
#PriorityWeightFairshare=100000
PriorityWeightAge=6000
#PriorityWeightPartition=10000
PriorityWeightJobSize=800
PriorityMaxAge=00:40:00
PriorityWeightQOS=5000
PriorityFlags=SMALL_RELATIVE_TO_TIME
此配置体现了短作业优先和 QoS 导向的策略,鼓励短小作业,并给予高优先级用户更多的资源倾斜。
最佳实践¶
pam_slurm_adopt¶
为了方便用户调试,超算集群通常会允许用户登录到此刻正在运行其任务的计算节点上,以方便调试程序,或者使用交互式的分配(salloc)。此前的 pam_slurm 虽然实现了这一功能,但无法在任务结束后自动收回资源,导致进程残留等一系列的问题。为此,Slurm 提供了新的 PAM 模块 pam_slurm_adopt,可以在用户登录时自动“认领”其正在运行的作业,并在用户退出登录后自动释放资源。
首先在 slurm.conf 中确认已经设置 PrologFlags=contain,并启用了 task/cgroup 和 proctrack/cgroup 插件。在所有计算节点上安装 libpam-slurm-adopt,修改如下配置文件:
/etc/ssh/sshd_config:确认UsePAM已启用。-
/etc/pam.d/sshd:在 account 部分添加:最前面的
-保证在模块不存在时,不会产生致命错误,从而阻止所有登录。
为了使得 pam_slurm_adopt 正常工作,还需保证:
- 禁用
pam_systemd模块,否则会与pam_slurm_adopt冲突,导致其失效。可通过pam-auth-update工具进行配置。 - 确保没有其他模块绕过了
pam_slurm_adopt。
潜在影响
禁用 pam_systemd 可能会导致某些依赖于 systemd 用户会话的功能(如用户级别的定时任务、用户级别的服务等)无法正常工作。
考虑到计算节点通常不需要这些功能,作者认为这是可以接受的权衡。
样例 PAM 配置
在作者管理的集群上,sshd 的 PAM 配置如下:
# PAM configuration for the Secure Shell service
# Standard Un*x authentication.
@include common-auth
# Disallow non-root logins when /etc/nologin exists.
account sufficient pam_listfile.so item=user sense=allow file=/etc/ssh/allowed_users onerr=fail
account sufficient pam_listfile.so item=user sense=allow file=/etc/ssh/allowed_groups onerr=fail
-account required pam_slurm_adopt.so action_adopt_failure=deny action_generic_failure=deny
account required pam_nologin.so
# Uncomment and edit /etc/security/access.conf if you need to set complex
# access limits that are hard to express in sshd_config.
# account required pam_access.so
# Standard Un*x authorization.
@include common-account
/etc/ssh/allowed_users 和 /etc/ssh/allowed_groups 额外列出了允许登录的用户和用户组,无论它们是否有正在运行的作业。作者还配置了更严格的 action_adopt_failure=deny 选项,进一步防止有用户进程残留。
Configless Slurm¶
在 20.02 版本后,Slurm 增加了 Configless 的功能,只需要在运行 slurmctld 的控制节点上维护一份配置,其他节点的 slurmd 或者 slurm 客户端在有需要时会自动拉取最新的配置,而在运行时进行 reconfig 也不用担心受到本地残留配置的影响。
文档指出,实现 configless 需要满足以下要求:
- 在
slurm.conf中配置SlurmctldParameters=enable_configless并重启 slurmctld; - 使得 slurmd 能找到 slurmctld:可以通过 DNS SRV 记录或者启动时传递
--conf-server参数,或者传递SLURM_CONF_SERVER环境变量; - 如果使用 SRV 记录,需要保证 slurmd 启动时本地没有任何配置(因为 搜索顺序 中 SRV 记录优先级最低)。
简单起见,可以选择传参的方案,即在所有安装 slurmd 的节点上修改 /etc/default/slurmd,在 SLURMD_OPTIONS 中添加:
(此部分可选)保险起见,还可以通过 systemd 对 slurmd 隐藏整个 /etc/slurm 的文件夹,避免潜在的冲突/混淆问题。运行 systemctl edit slurmd,增加:
trixie 前的特殊配置
较旧(trixie 前)的 slurmd.service 中含有多余的 ConditionPathExists=/etc/slurm/slurmd.conf,需要一并覆盖清除,否则会导致无配置的情况下,服务无法正常启动:
如果有未安装任何 slurm 守护进程的节点(即“瘦”登录节点),需要安装 sackd(从 25.05 开始提供),负责请求控制器、拉取缓存的配置供 srun 等客户端程序使用:
apt-get install -y sackd
echo 'SACKD_OPTIONS="--conf-server your_ctl_server:6817"' >> /etc/default/sackd
systemctl enable --now sackd
延伸阅读¶
此部分简述 Slurm 近年的新功能,供有兴趣的读者进一步探索。
Slurm 与容器的集成¶
目前有大量的高性能计算工作负载已经迁移到了容器化环境中运行,Slurm 也提供了对容器的原生支持,这包括两步:
首先,Slurm 任务可以运行在容器中:通过配置 Slurm 的 oci.conf,让 Slurm 可以在计算节点上调用容器 OCI 运行时(如 runc, crun, nvidia-container-runtime 等)。用户可以通过 srun --container $OCI_BUNDLE 来提交作业,Slurm 会根据配置,在计算节点上启动指定的容器,并在容器内运行用户的作业。也就是说,具体的容器运行时对 Slurm 用户是透明的。
进一步地,Slurm 还可以作为 OCI 容器运行时(“后端”):用户在提交作业时不需要使用 slurm 相关命令,而是直接使用 podman, dockers 或者 singularity 等前端工具,它们通过标准 OCI 接口调用 Slurm 的 scrun 命令来创建和运行容器,而 Slurm 会将容器提交到计算节点上运行。也就是说,Slurm 本身也对容器用户是透明的;最终效果是,用户可以像在单机上运行容器一样,在集群上运行容器,而不需要关心底层的调度和资源分配。
配置复杂
目前 Slurm 对容器的支持仍然比较初级,配置较为晦涩难懂(如对共享文件系统有更复杂的要求),且对不同的容器运行时支持程度不一,限制较多。作者尚未成功配置过此功能,建议有兴趣的读者仔细阅读官方文档,谨慎部署。
Slurm Restful API (slurmrestd)¶
通过运行 slurmrestd 守护进程,可以为 Slurm 提供基于 RESTful 的 API 接口,方便用户和管理员通过 HTTP 请求与 Slurm 进行结构化的数据交互,而无需拼接命令、解析文本。很多图形化的作业提交平台正是基于此接口实现的。
slurmrestd 支持多种认证方式,包括 JWT、UNIX domain socket 本地认证和认证代理(类似 Grafana)。
可参考: